
Zespół algorytmików z Wydziału Matematyki, Informatyki i Mechaniki UW stara się opisać zjawiska zachodzące na Twitterze: jaka jest szansa, że plotka opublikowana przez jedną osobę trafi do ponad tysiąca innych, w jakim tempie plotka będzie się rozchodzić, jakie cechy musi mieć sieć społecznościowa, żeby plotka rozchodziła się w taki sam sposób jak na Twitterze?
Odpowiedzi na te pytania znalazły się w pracy „Why Do Cascade Sizes Follow a Power-Law?”, autorstwa prof. Piotra Sankowskiego oraz jego zespołu, która została przyjęta na konferencję International World Wide Web Conference (odbędzie się 3-7 kwietnia 2017 w Perth w Australii).
Konferencja, organizowana od 1994 roku, uznawana jest za jedno z najbardziej prestiżowych wydarzeń dotyczących przyszłości internetu. W tym roku z ponad 1000 zgłoszonych prac przyjęto jedynie 164.
Rozkład popularności plotek
Liczba osób, do których trafi informacja, może być szacowana przy użyciu prawdopodobieństwa. Szansa na to, że plotka dotrze do wielu osób jest w rzeczywistości bardzo niewielka. Z danych empirycznych wynika, że jedynie 0.1 promila wszystkich plotek na Twitterze dociera do ponad 2500 osób.
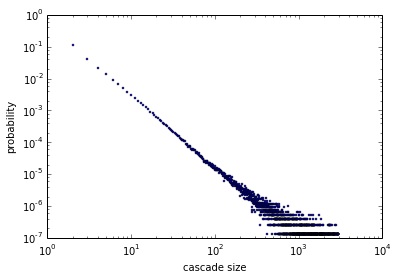
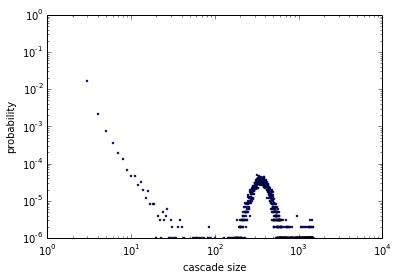
Dotychczasowe modele, którymi naukowcy zajmują się od ponad 10 lat, nie opisywały dobrze stanu faktycznego. Na wykresach nr 1 i 2 przedstawione jest „prawdopodobieństwo”, że losowa plotka będzie miała zadany „rozmiar” (osie wykresu dla czytelności zostały przeskalowane logarytmicznie). Jak widać, wyniki eksperymentów znacznie odbiegały od rzeczywistych danych, gdzie o plotce dowiadywało się zdecydowanie zbyt wiele osób.
Wykres nr 2 przedstawia wyniki działania Cascade Generation Model (CGM), najpopularniejszego w tej dziedzinie. Inne dotychczasowe modele dawały bardzo podobne oszacowania, w szczególności taki sam „garb” dla prawdopodobieństwa, że plotka dotrze do wielu osób (na wykresie pomiędzy 10^2, a 10^3).
Nowy sposób
W pracy „Why Do Cascade Sizes Follow a Power-Law?” zaproponowano nowy model, w którym rozkład plotek jest linią prostą (zbliżoną do prawdziwych danych), czyli szansę na to, że plotka dotrze do określonej liczby osób, opisuje tzw. „rozkład potęgowy”.
Poza nowym modelem, który w porównaniu z innymi bardzo dobrze opisuje rzeczywistość, przedstawiono również metodę na generowanie sieci (grafów) o cechach zbliżonych do Twittera. Otóż każda osoba może przekazać plotkę do jednej osoby, do kilku następnych, albo do żadnej. Trasa plotki (nazywana „kaskadą informacji”) to ścieżka, pokazująca do jakich użytkowników dotarła i jaką drogą.
W pracy zaproponowano nowy sposób generowania kaskad, taki że rozchodzenie się w nich plotek ma takie same cechy (rozkład prawdopodobieństwa) co rozchodzenie się plotek na Twitterze. Jest to zupełnie nowy sposób weryfikowania tego typu modeli. Do tej pory należało przeprowadzić ogromną liczbę symulacji i porównać ich wyniki z prawdziwymi danymi. Korzystając z nowej metody, poprawność modelu może być sprawdzana szybciej przy użyciu mniejszej ilości danych.
Zastosowania badań teoretycznych
Jednym z zastosowań wyników pracy „Why Do Cascade Sizes Follow a Power-Law?” jest testowanie wydajności. Do tej pory, aby sprawdzić czy duży system informatyczny przetrwa wysokie obciążenie użytkowników, trzeba było przeprowadzić symulacje przy użyciu ogromnej ilości danych. Teraz można wykonać taki test mniejszym kosztem (energii, czasu, danych). – Nasz model pozwoli tanio sprawdzić czy narzędzia wytrzymają obciążenie – komentują autorzy pracy.